

 988
988 11
11聊点稍微硬核一点的,填个之前的坑,面向非码农非AI从业者的AI模型入门。“浅”谈GPT背后模型的真实,你将听到主播尽力用大白话解释的如下内容:
- 神经网络和AI工作原理
- 神经网络的输入、输出、训练
- 词向量 word embedding/one-hot/word2vec
- 梯度下降
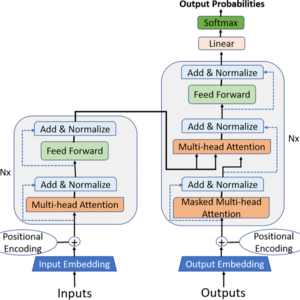
- seq2seq,encoder-decoder
- attention机制的具体运作
- transformer框架
无公式无复杂数学,可放心食用。同时主播水平有限,为了尽量让意思好理解可能有些错误,若有纰漏,烦请指正,提前抱歉!
主播:松阴
节目开始前,请大家加入听友群(加群方法见播客介绍页),以及帮忙多多转发!
00:53 “免责声明”
03:00 GPT到底指的是什么?
04:27 AI就是用数值化的方法对世界做参数估计
05:44 为什么是神经网络?
07:14 从one-hot encoding开始,把文字输入变成数值向量
09:32 模型输出和如何训练(损失函数和优化模型)
13:18 更好的输入:词向量 word embedding (word2vec, glove, …)
19:23 梯度下降、梯度爆炸/消失
23:03 生成式、语言模型、seq2seq
26:00 RNN 循环神经网络
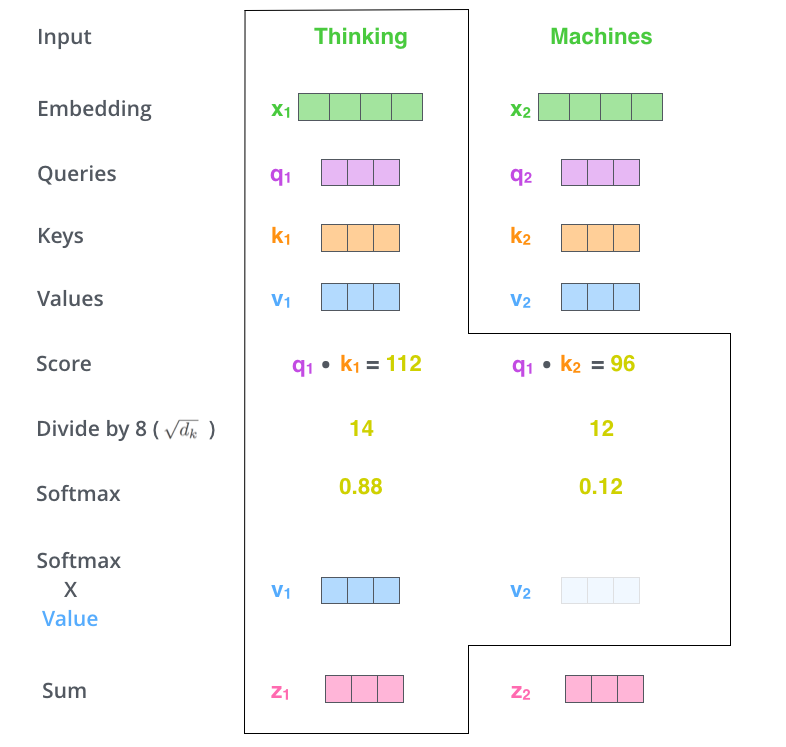
28:48 Attention 注意力机制
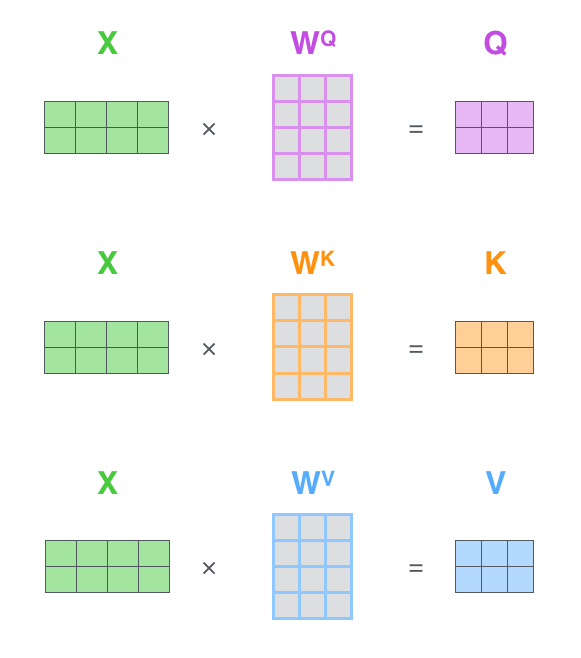
31:06 query, key, value 详解attention机制
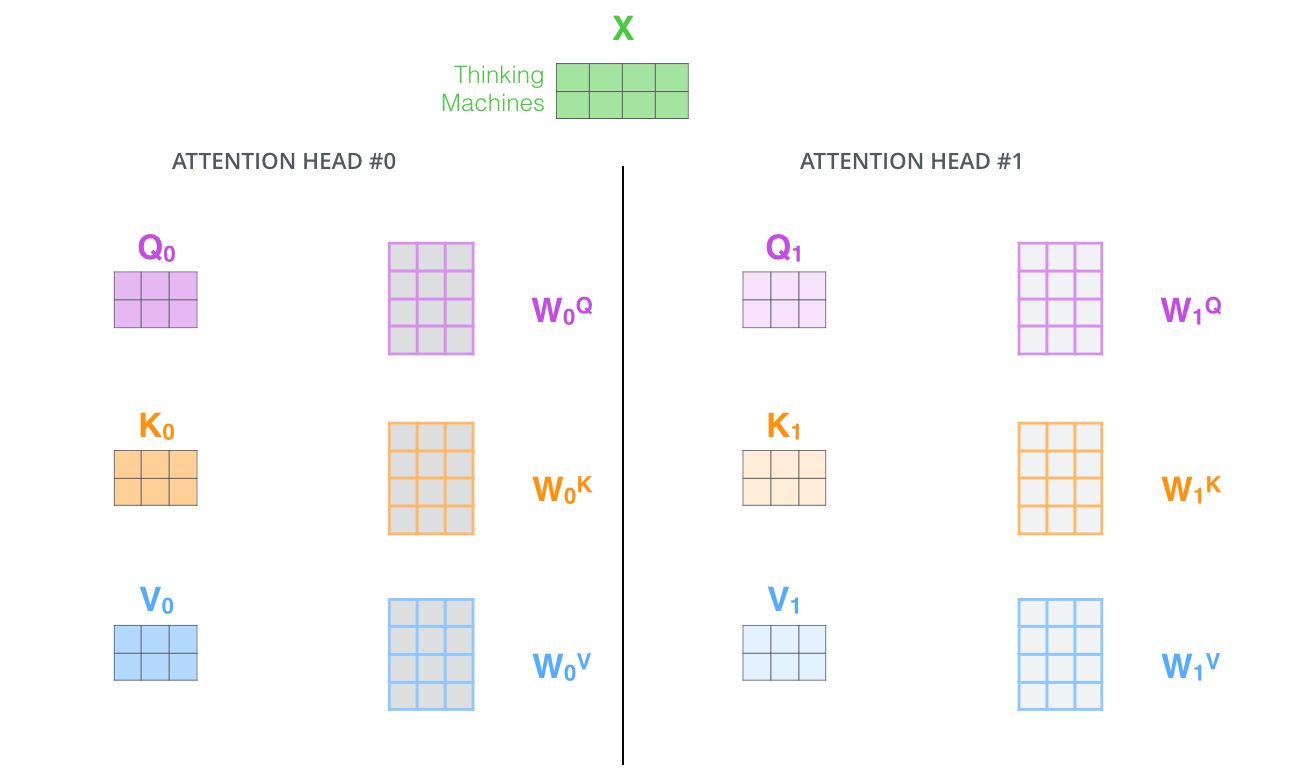
35:00 multihead 多头注意力
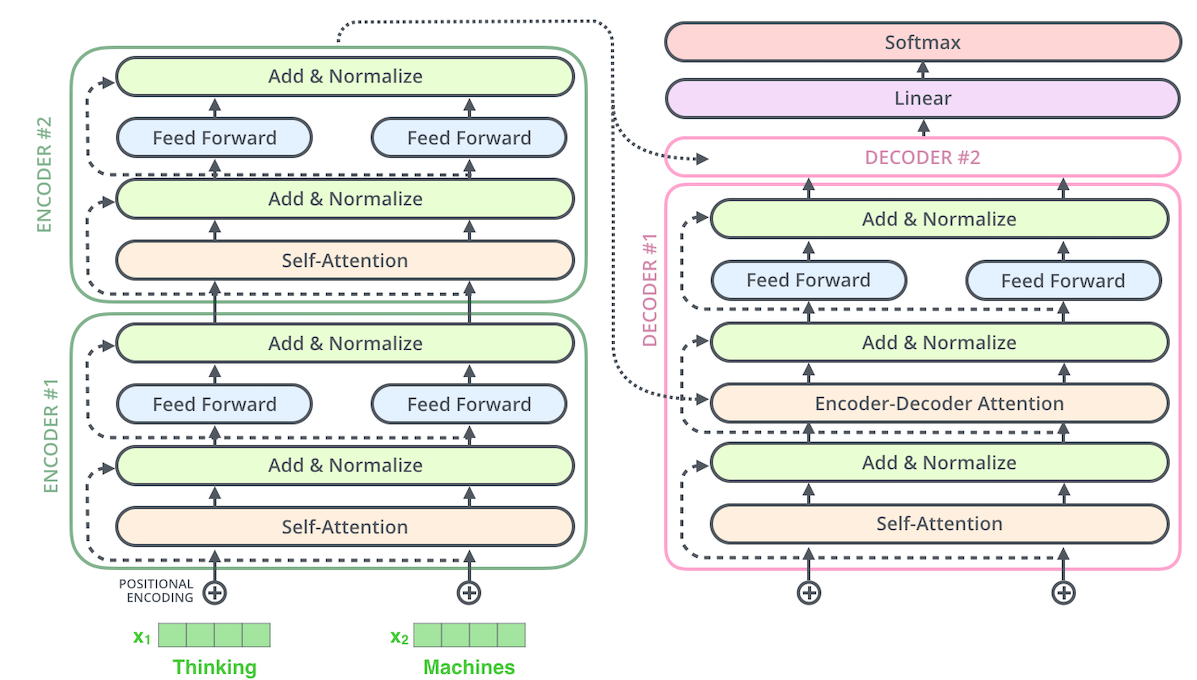
37:50 attention到Transformer
39:10 positional encoding 位置编码
41:16 训练解码器decoder需要masked attention
42:42 最终decoder生成结果需要结合encoder输出和decoder本身attention
延展资料
Transformer框架
attention里的query/key/value
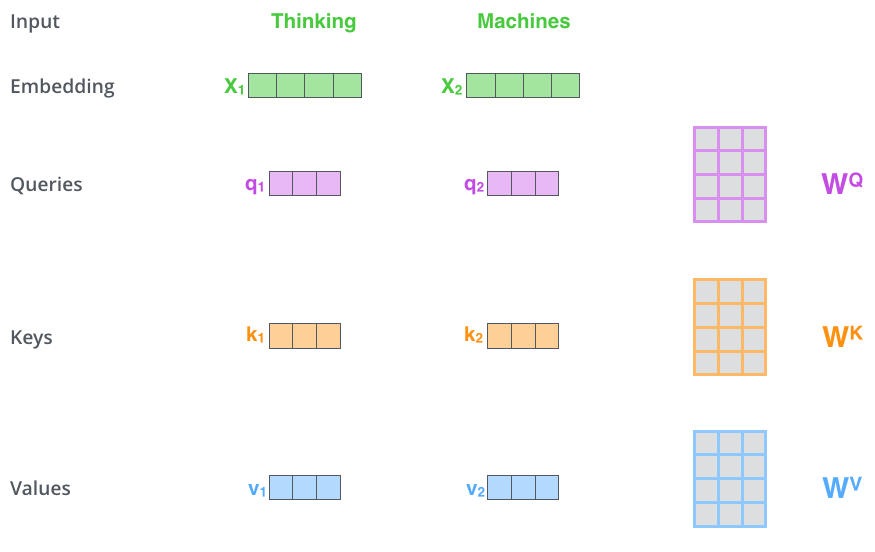
多头注意力
带你可视化了解seq2seq jalammar.github.io
带你可视化了解attention和 transformer jalammar.github.io
PyTorch的Transformer代码教程 nlp.seas.harvard.edu
attention is all you need arxiv.org








All Your Need Is Love ~ Beatles