

 5
5 0
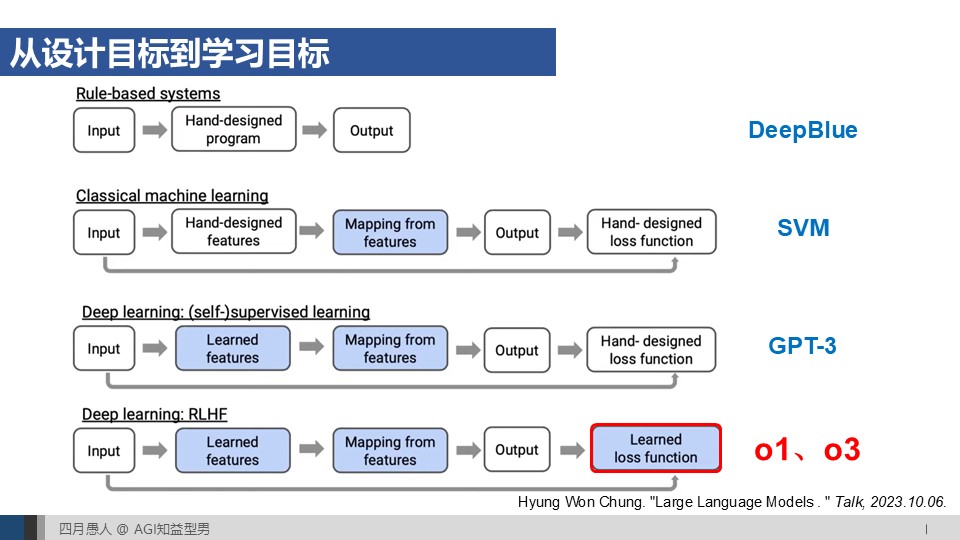
0第一期播客里提到IIya把AlphaGo的思想应用到o系列的研发中。大模型的预训练、后训练和推断很好地对应了AlphaGo的三个阶段:基于人类已有数据的离线模仿学习、对策略函数增强和估值函数训练的离线强化学习、基于蒙特卡洛树搜索的在线推断。这一期我们从技术的角度深入讨论这一点,从DeepMind的Alpha系列来理解o系列的发展。
00:57 大模型三阶段 vs AlphaGo三阶段
01:05 o系列技术分析
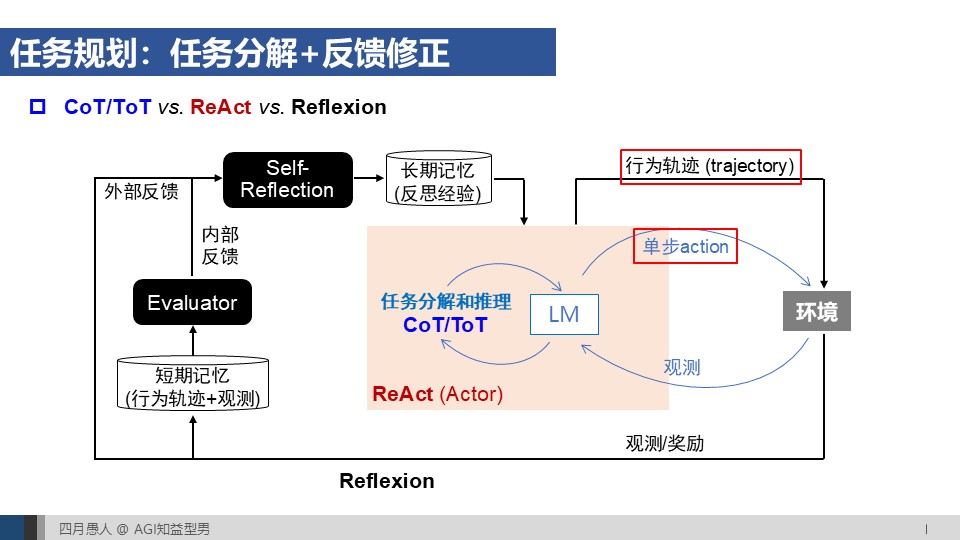
03:08 基于提示工程(Prompting)的大模型推理
04:59 基于监督学习的大模型推理
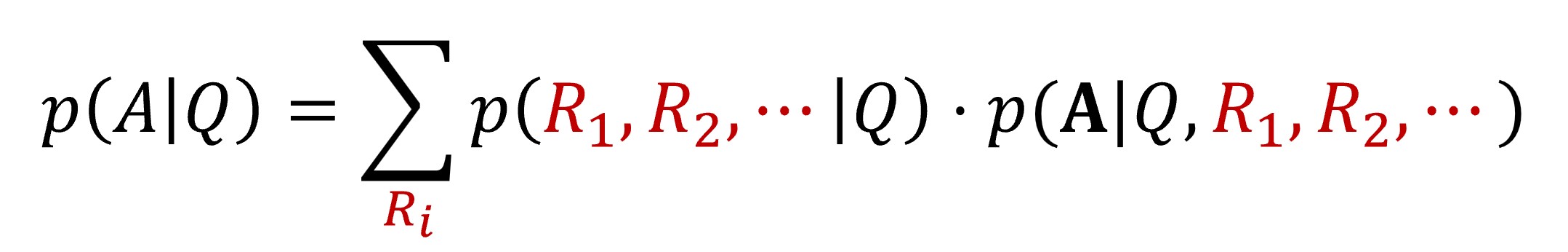
06:36 基于强化学习的大模型推理
09:33 突破人类记录的{Q,A}数据
10:02 系统1+X -> 系统2+X

11:29 连续思维链
12:45 Bitter Lesson: Data is all you need

16:40 o系列面临的挑战
17:59 o系列泛化的挑战一:奖励函数和行为空间的适配 -> 强化微调
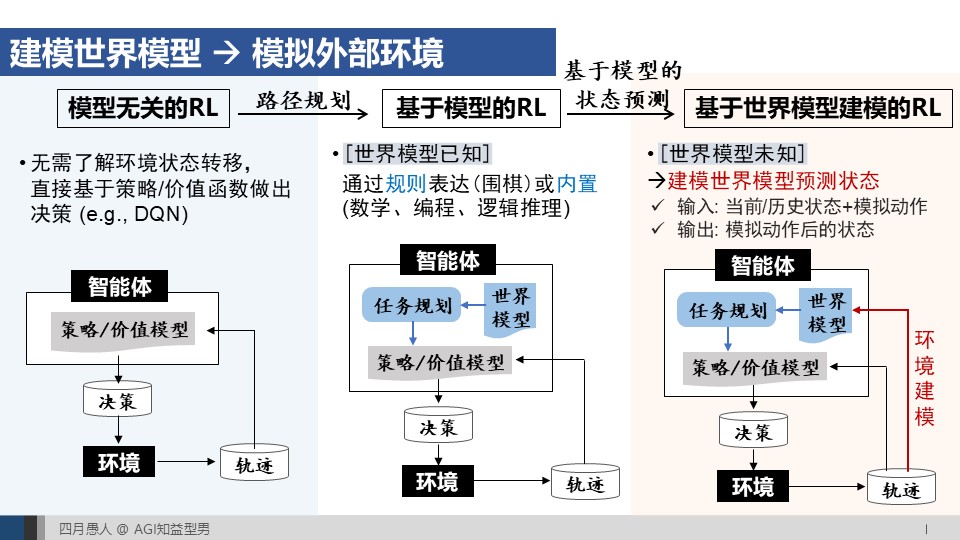
25:08 o系列泛化的挑战二:无完美模拟器场景下的环境状态预测 -> 世界模型建模
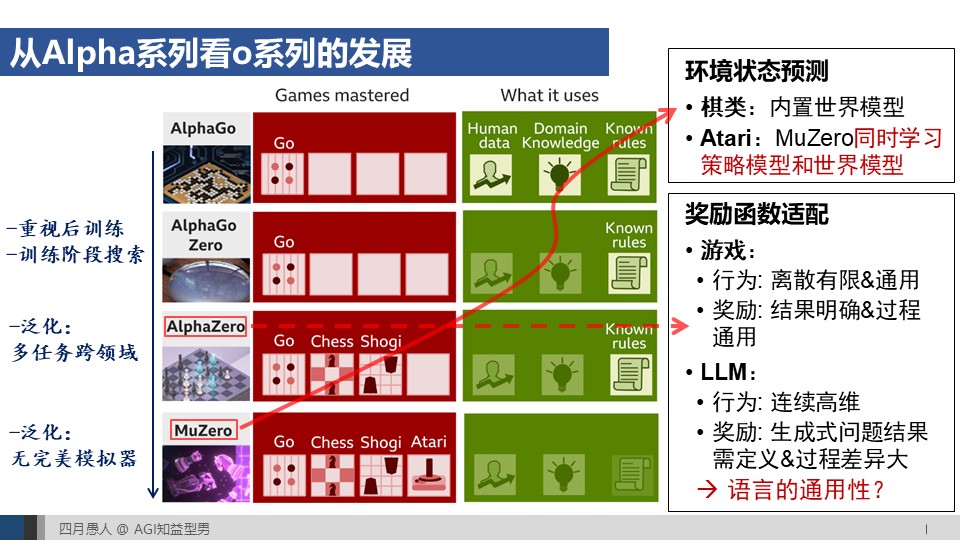
29:50 从Alpha系列发展看o系列
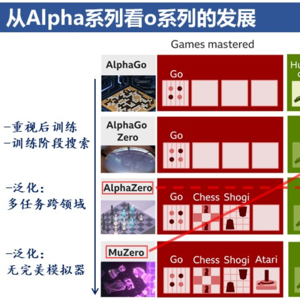
30:55 AlphaGo Zero vs o1: 重视后训练+在训练阶段搜索
32:30 o3的技术分析
34:02 AlphaZero: 多任务和跨领域泛化,MuZero:无完美模拟器场景下的泛化
35:06 MuZero对o系列挑战二的启发
35:49 Alpha系列对o系列挑战一的启发
参考资料:
[OpenAI o1研究员Hyung Won Chung的报告]:
- "Large Language Models . " Talk,2023.10.06.
- “Don’t teach, incentivize . " Talk,2024.09.19.
[IIya介绍SelfPlay的报告]:
"Meta Learning & Self Play." 2018.
[连续思维链]:
-Language is primarily a tool for communicationrather than thought. Nature, 2024.
-Training Large Language Models to Reasonin a Continuous Latent Space.
