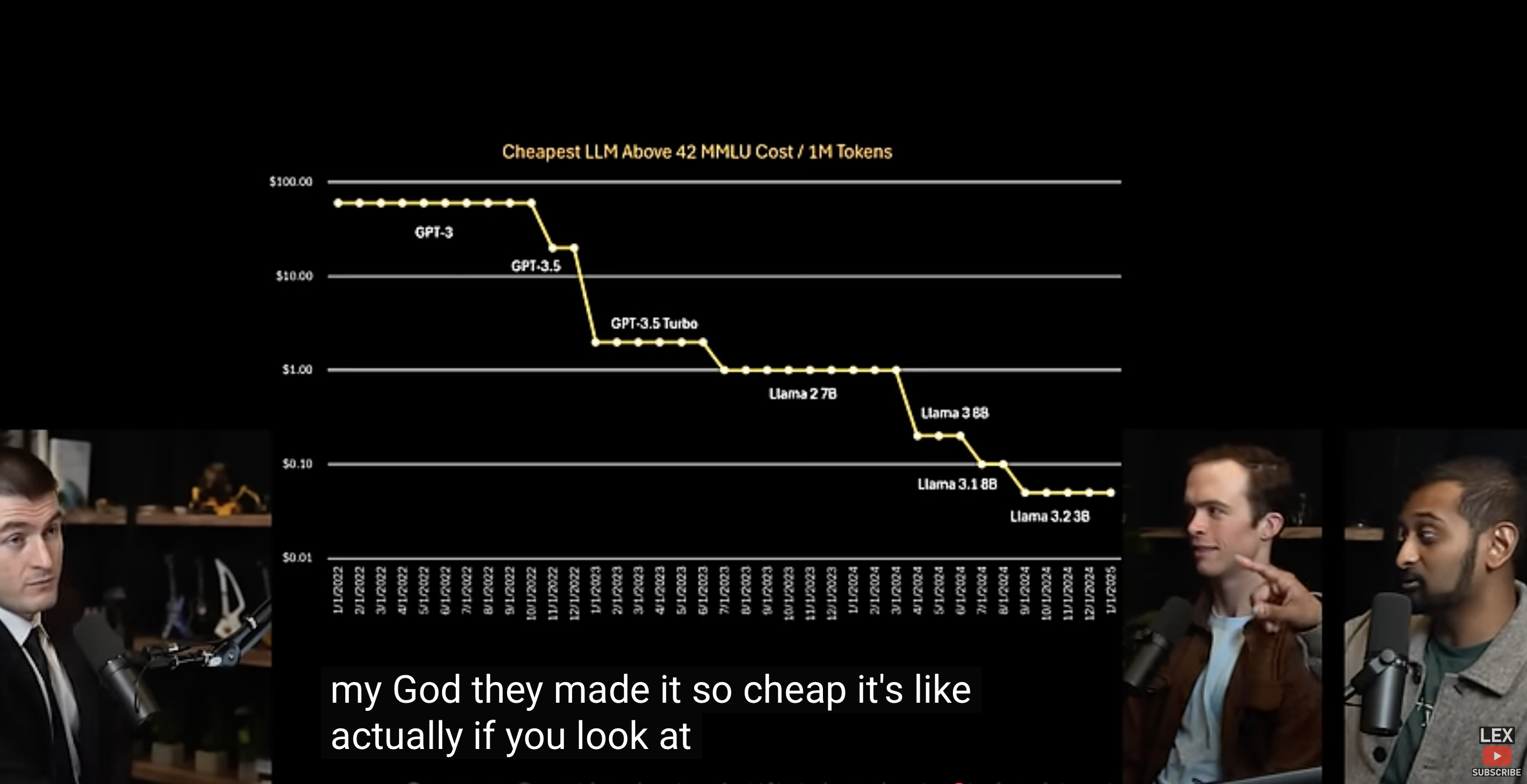
440
440 11
11AI正在成为这个时代最重要的变革力量,但它的讨论却常常充满门槛。术语的混乱让外行难以理解,信息的碎片化让人难以构建完整的认知。这期节目,希望让 AI 不再是少数人的“黑话”,而是所有人都能真正理解、思考并参与塑造的未来,因为未来属于那些真正理解它的人。
我将以Lex Fridman最新一期长达5个小时的播客中的热门话题和精彩观点为基础,深入浅出地解释他们讨论中的核心 AI 概念,比如“AI行业里并没有达成一致的关于开源的定义”、“大模型的参数权重”、“预训练 vs. 后训练”、“对齐”、"Token"、“思维链chain of thoughts"、“MoE“、“DeepSeek绕开英伟达"、“集群”、“AI智能体AI Agent"等。
01:43 先介绍一下三位人物,Lex Fridman...
03:06 DeepSeek和OpenAI之争,被很多媒体和自媒体简单的说成了"开源"与"非开源"之争。
03:16 在人工智能领域,关于"开源"的定义到目前为止并没有完全统一一的一个共识。
06:29 大模型的参数权重,就像是大模型的记忆力,他们存储了模型从海量数据中学到的模式、规律和知识。
07:37 权重的公开并不等于模型完全开源。
08:17 Nathan所在的研究机构认为,真正的开源应该不仅仅包括开放源代码,还应该包括:发布训练数据,发布训练代码,并且发布参数权重。
08:54 接下来我先介绍“预训练”和“后训练”。
09:30 在像GPT这样的大语言模型当中,Token是一个是文本中的一个较小的单元,可能是一个单词、一部分单词,甚至是一个标点符号。
11:31 在人工智能领域,对齐、alignment,主要是指确保AI系统的行为和目标,与人类的意图、价值观和期望一致。
13:53 预训练通常成本更高,训练时间更长。
14:13 接下来再介绍一下“推理过程的显性化”这个概念,也就是大家从DeepSeek R1中看到的,R1完整的展示了整个推理的逻辑。
15:07 相比于传统的黑箱模型,Chain of Thoughts有助于帮助人类理解模型是如何做出判断的,从而提升了整个模型的可信度。
15:41 这个“混合专家系统” MoE的核心思想是...
16:15 在OpenAI实现MoE架构之前,行业里没有人相信这个MoE的paper真能work...
16:49 关于DeepSeek没有直接去直接调用英伟达CUDA API,也就是NCCL API(绕过英伟达)...
18:31 谈到当前人工智能领域的数字集群的规模...
21:01 除了电力供,GPU的冷却也是一个大问题。
21:30 未来,谁最可能成为英伟达的竞争对手或者是替代品?
22:42 目前在人工智能领域,谁在赚钱?
23:11 关于AGI,通用人工智能...
23:30 关于未来AI的价值到底会从哪种形式呈现...
23:39 这里又提到了AI agent(AI代理)的概念...
24:12 OpenAI前几周发布了自己的第一个AI agent, 这个产品的名字叫做OpenAI Operator.
25:48 他们三位也谈到了程序员与AI之间的关系,以及未来的发展