


 198
198 2
2从早期的DNA Bert到不久前发布的革命性的模型EVO 2,基因组预测技术在DNA语言模型的加持下不断飞速发展。本期主持人lotus作为嘉宾,与北京大学基因组学方向的博士研究生小蛇一起分享在一线工作中对DNA语言模型的理解。
与传统大语言模型不同,DNA语言模型面临着处理人类基因组长达32亿碱基对这一超长序列的巨大挑战。斯坦福大学和Arc Institute团队的最新研究成果EVO 2模型通过创新的Hyena架构,将上下文窗口扩展到百万级别,将处理小型细菌基因组变为可能。这种架构在序列长度增加时计算效率显著提升,为未来处理更复杂的真核生物基因组铺平了道路。
而伴随着CRISPR-Cas等基因编辑技术的发展应用,DNA语言模型可能会变得更加精确和高效,也许不远的将来我们就可以像使用Midjourney一样,通过简单的提示词来设计基因序列。虽然目前还面临着许多挑战,AI驱动的DNA语言模型会不断改变生物技术领域的格局,同时随着在基因治疗领域的深入应用,个性化医疗、新型疫苗研发等人类医疗健康领域也将发生革命性的改变。
【嘉宾介绍】
小蛇,北京大学二年级的博士研究生,研究方向是基因组学,目前参与跟基因组相关的大语言模型的工作。
【主要话题】
02:52 DNA语言模型的简单介绍
04:04 DNA语言模型是否会取代蛋白质结构预测模型的作用及其局限性
08:09 Evo 2 的进展与突破以及一个关于资方的小八卦
11:04 Evo 2 与Evo 1对比,hyena架构设计与计算优化
14:36 pre-training究竟是否可以提升DNA语言模型的表现?
16:40 Is DNA all you need?
18:26 DNA语言模型的理想功能及其在基因调控网络等领域的潜在突破点
20:01 DNA语言模型的难点:仅有的4个token和超长上下文的挑战
21:03 Evo模型在突变预测、基因重要性分析等任务上的表现及其实际意义。
26:14 CRISPR相关系统的工作原理及其在基因编辑和药物开发中的应用,以及通过大语言模型设计single guide RNA以改进基因编辑疗法
31:21 EVO团队在DNA语言模型中的领先地位的讨论
35:44 关注科学问题的本质,寻找适合AI发挥作用的领域
【Reference】
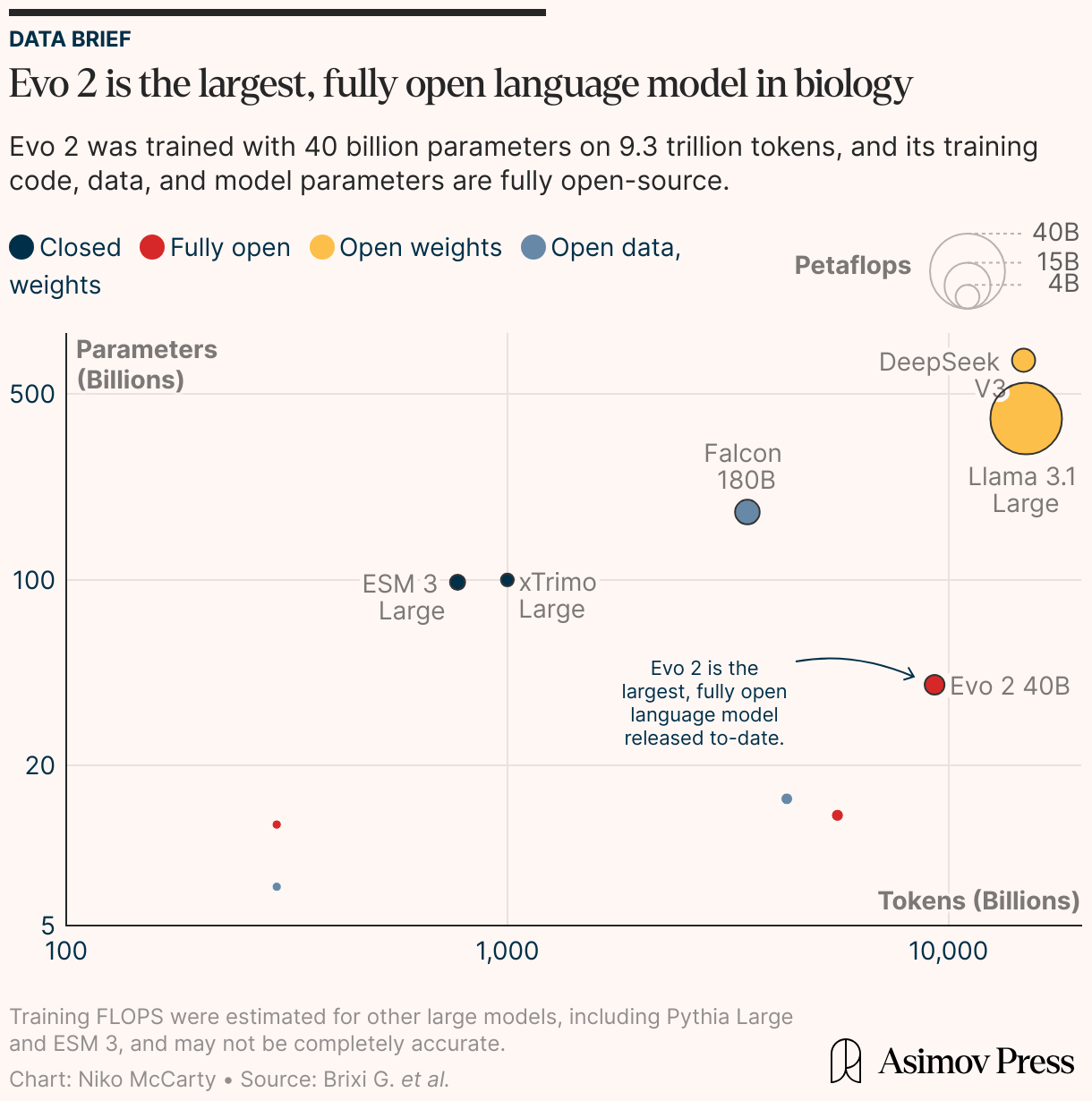
最大的生物AI模型:Evo 2 Can Design Entire Genomes
Arc Institute团队发布的EVO系列模型:
Evo: DNA foundation modeling from molecular to genome scale
AI can now model and design the genetic code for all domains of life with Evo 2
对于pre-training的不同看法:
Genomic Foundationless Models: Pretraining Does Not Promise Performance
封面图源:Evo 2
欢迎在评论区留言交流。想要了解更多每日AI与生物科技前沿的讨论与分享,可以关注小红书:
各类合作或嘉宾自荐,请添加微信:Lostu_wd

